Парсинг семантики через Key Collector
Важное обновление
Модуль XML-River прекратил поддержку Key Collector — парсинг Вордстат через программу сейчас технически недоступен (парсинг Google — тоже). Гайд оставляем как справочный: этапы работы с минус-словами, дублями и кластеризацией актуальны. Для сбора семантики из Вордстата используйте нашу программу Wordstat DeepDive.
Рассмотрим процесс парсинга запросов Вордстат через Key Collector: от импорта фраз до выгрузки итогового файла с ключевыми словами и минус-словами.
Выгрузка файла импорта из Google Sheets в Key Collector
- 01 Сначала собираем маски ключевых слов в Вордстате и загружаем их в файл импорта — можно сразу разбить по группам, так удобнее парсить. Пример таблицы.
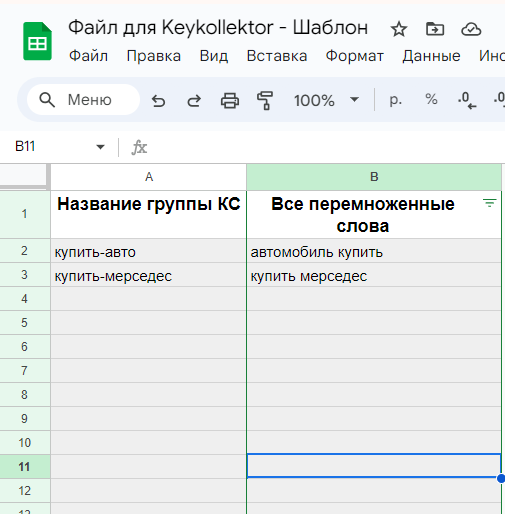
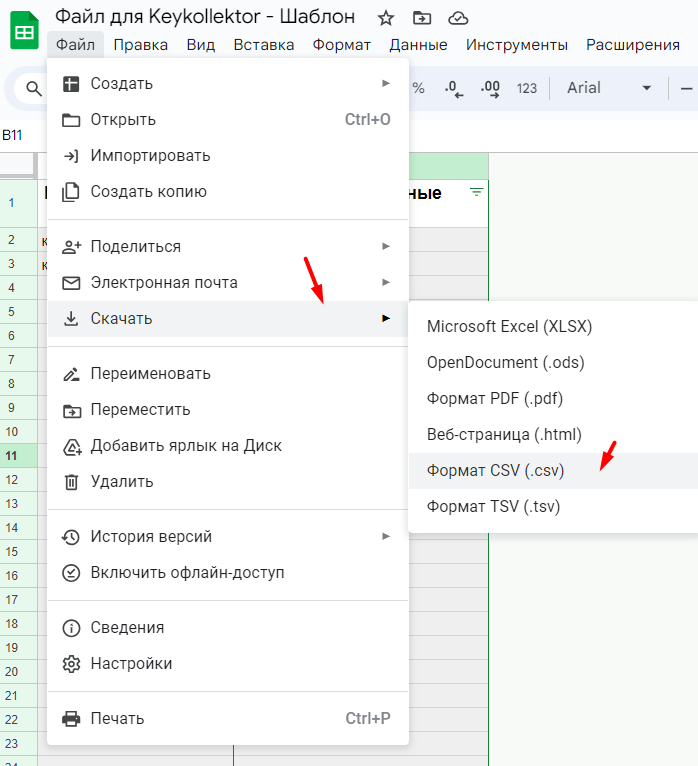
- 02 После заполнения таблицы скачайте файл в формате CSV.
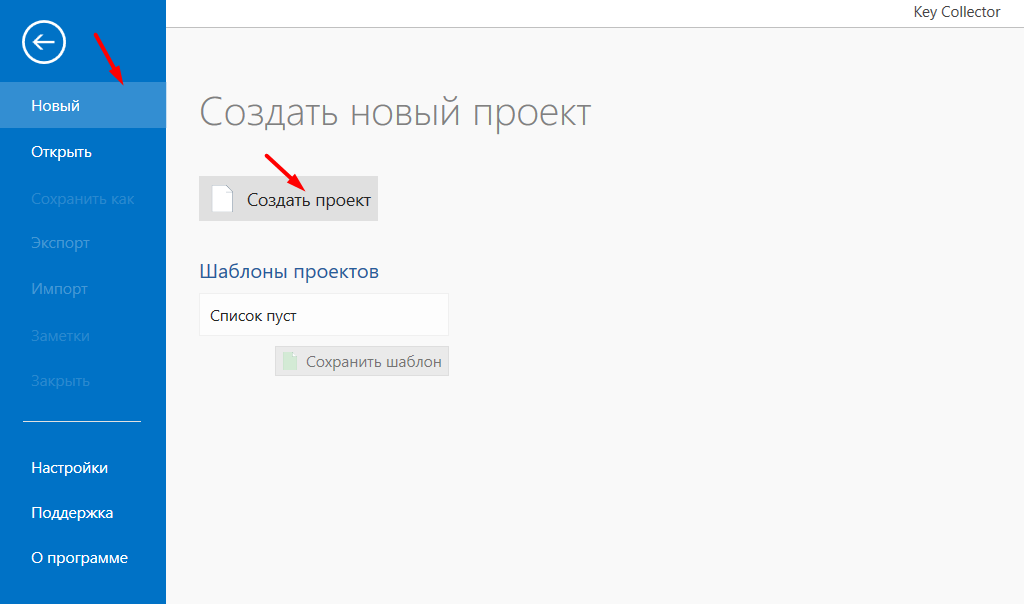
- 03 Переходим в Key Collector и создаём новый проект. Называем его — после создания откроется основной интерфейс.
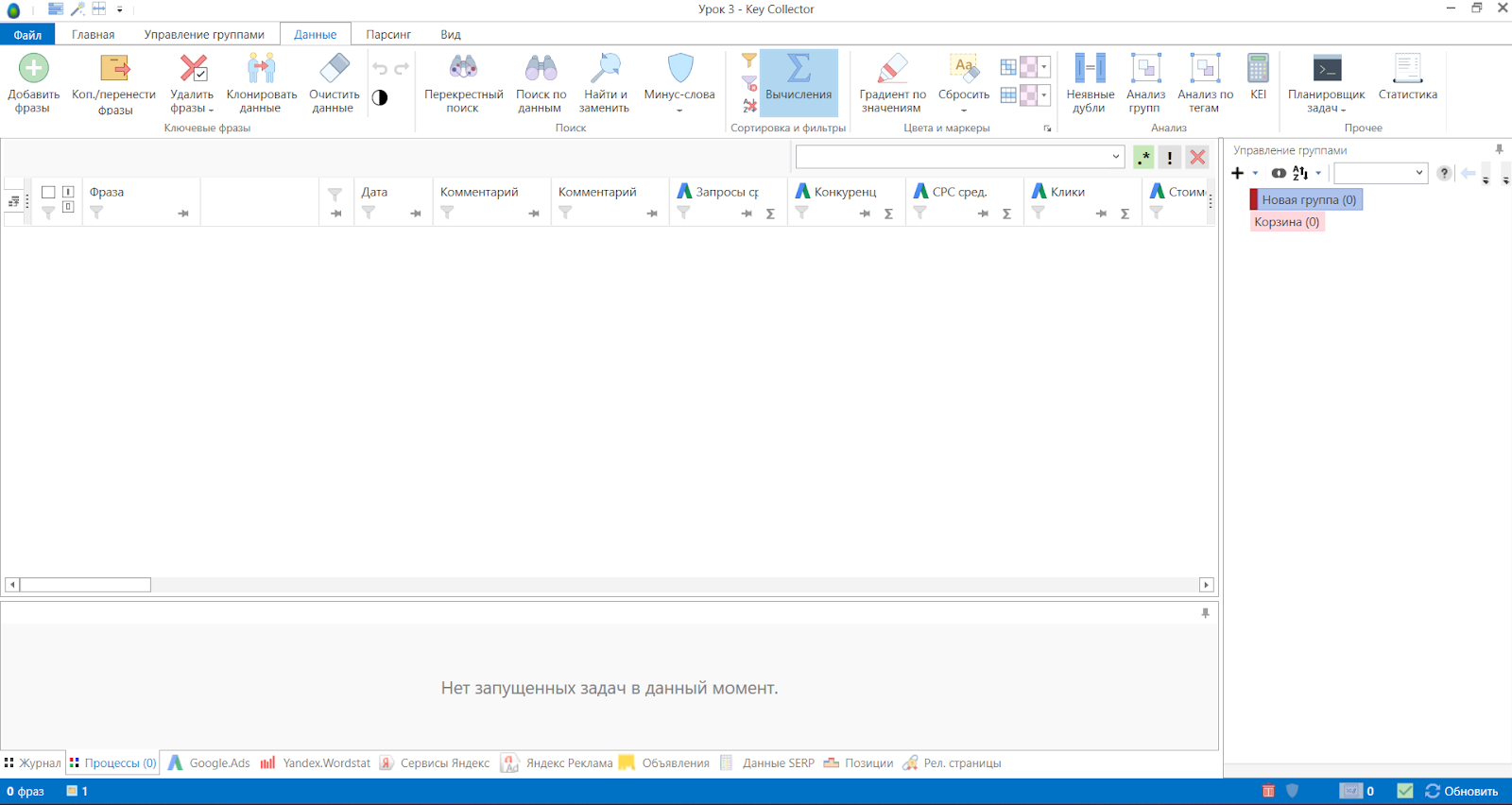
- 04 Нажимаем «Файл» → «Импорт» → «Данные CSV».
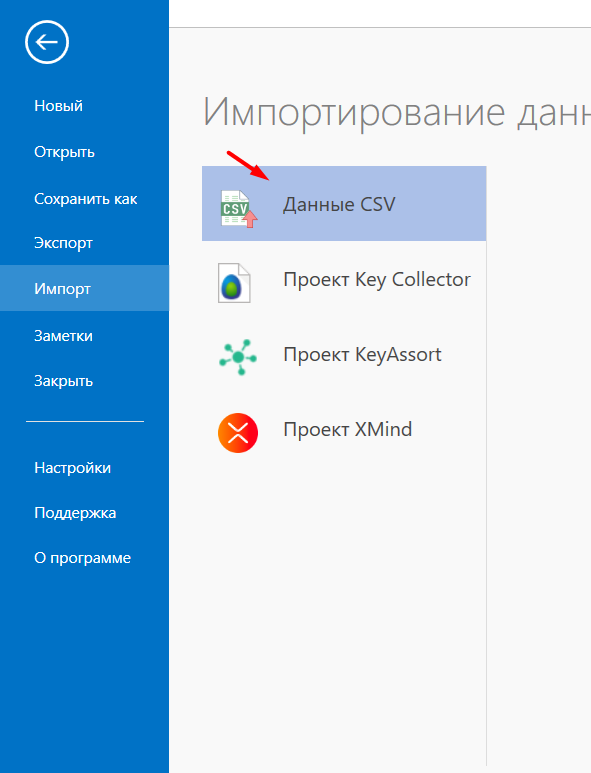
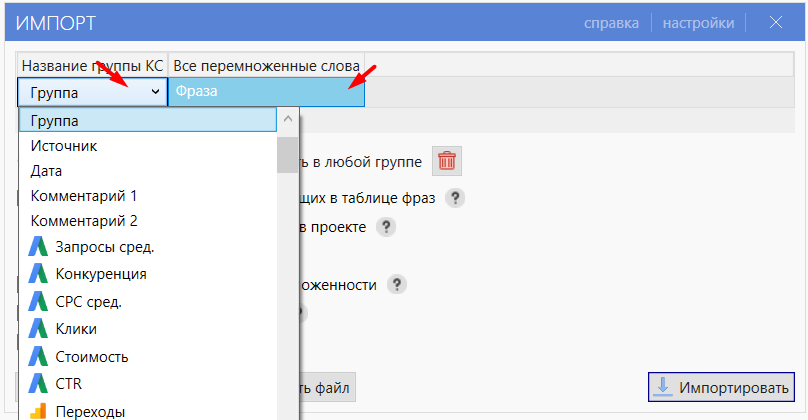
- 05 Выбираем наш CSV-файл. При первом импорте настройте схему данных — сопоставьте столбцы таблицы с определениями Key Collector (например: «Название группы КС» = Группа, «Все перемноженные слова» = Фраза).
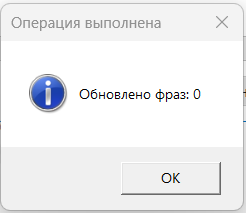
Нажимаем «Импортировать» — при успехе увидите такое сообщение:
- 06 Возвращаемся по стрелке сверху слева в проект — справа будут ваши группы объявлений и фразы.
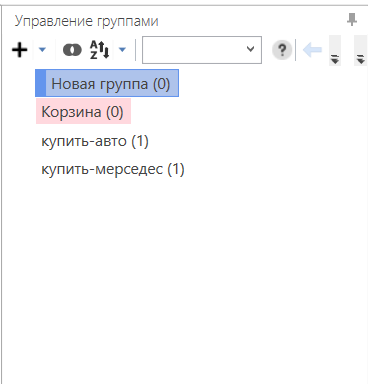
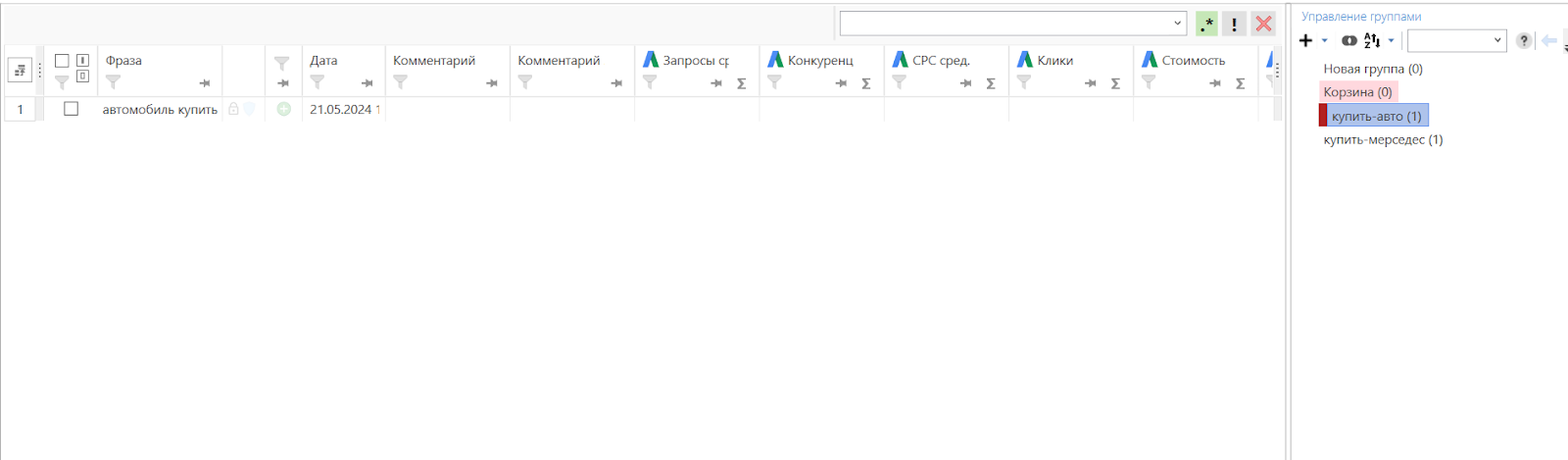
Выгрузка ключевых фраз напрямую, без файла
Фразы можно загружать и без файла импорта, но тогда они попадут в одну группу, которую придётся кластеризовать уже в Key Collector.
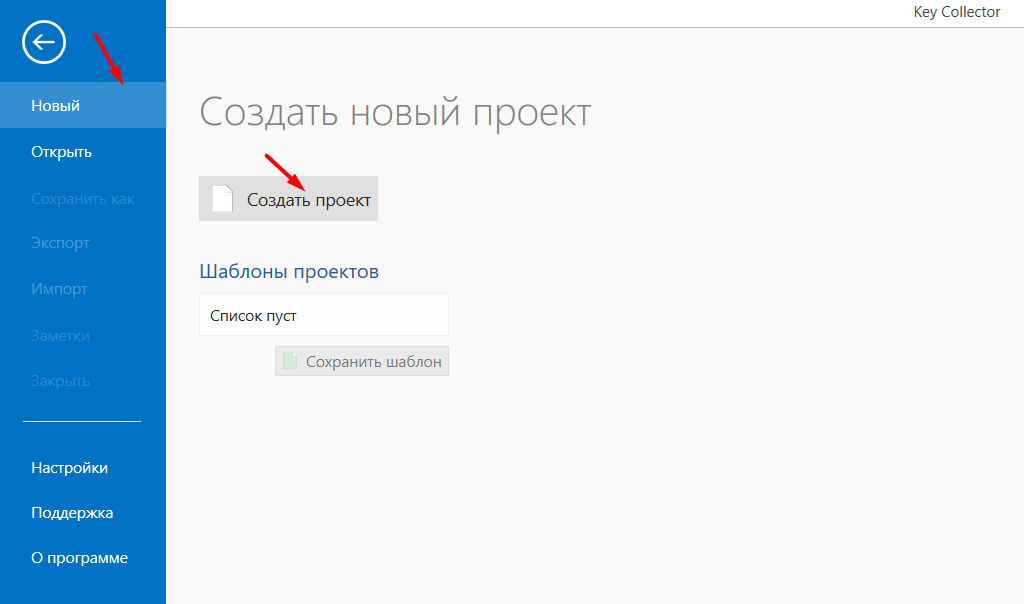
- 01 Создайте новый проект.
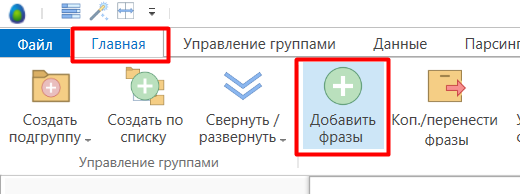
- 02 На вкладке «Главная» нажмите кнопку «Добавить фразы».
- 03 Внесите список фраз (собранных заранее в Вордстате) и нажмите «Добавить».
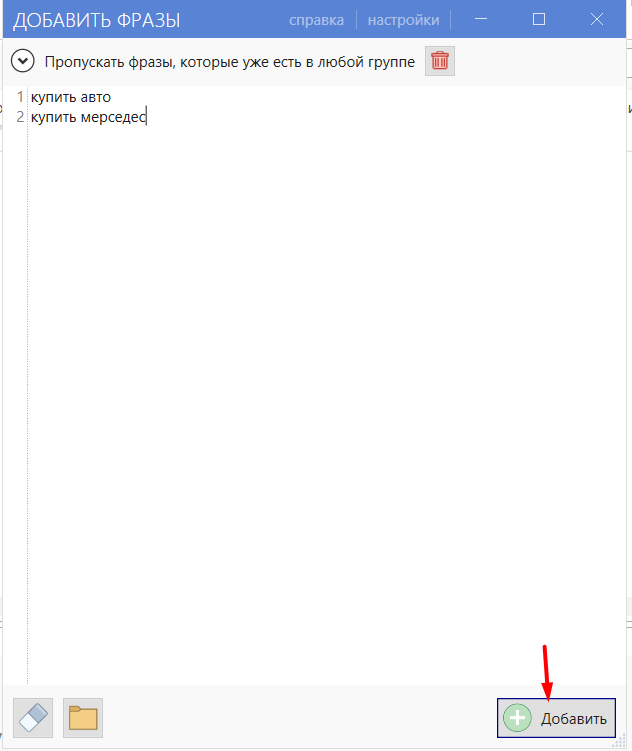
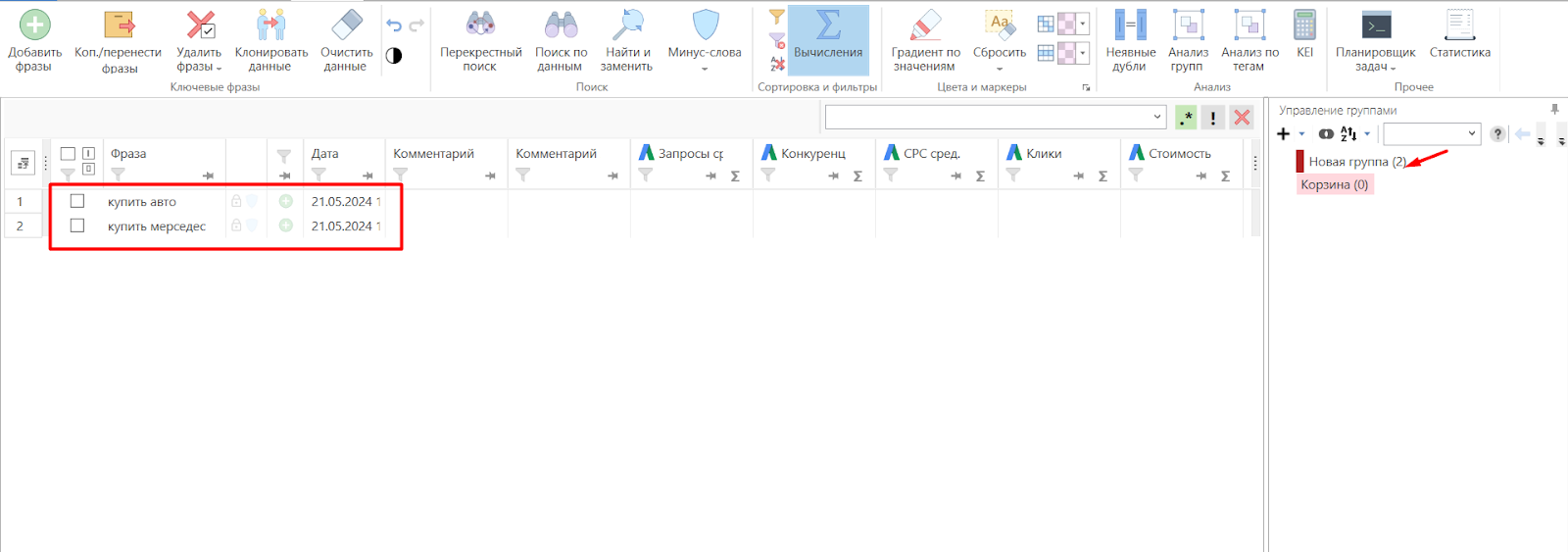
- 04 После добавления фразы попадут в «Новую группу» и отобразятся в интерфейсе.
Настройки в парсере XML-River и запуск парсинга
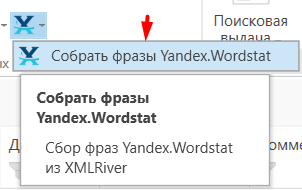
- 01 Для парсинга используем дополнение XML-River: вкладка «Парсинг» → значок XML-River → «Собрать фразы Яндекс Вордстат».

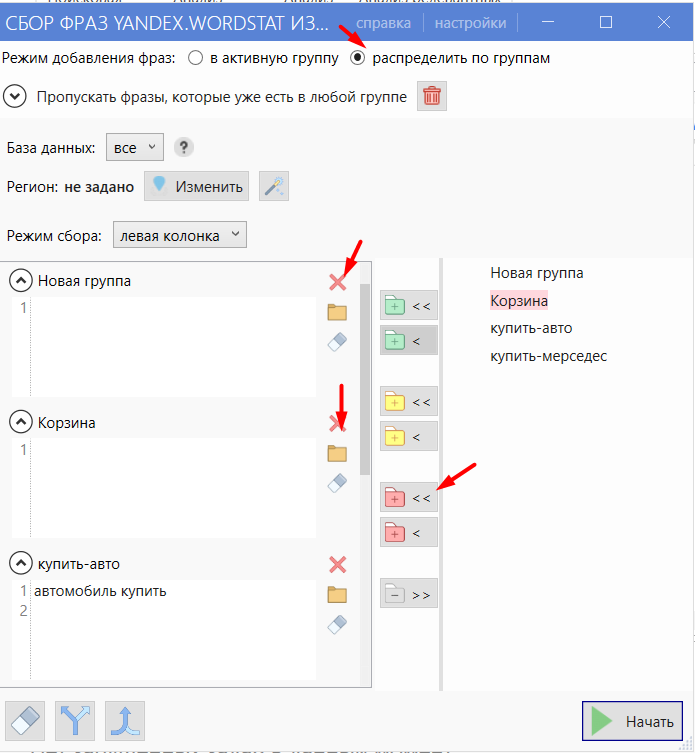
- 02 Чтобы собрать фразы сразу для всех групп, выберите режим добавления фраз «Разбить по группам» и импортируйте все группы красной кнопкой. Ненужные (корзину, пустую новую группу) удалите. Тут же выставьте регион.
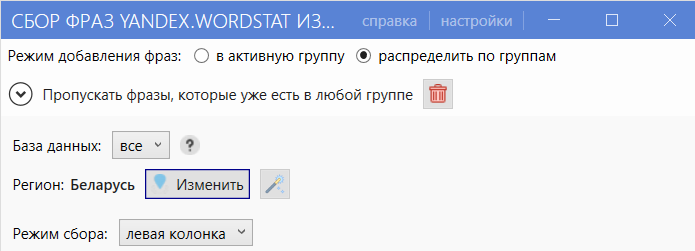
- 03 Перейдите в настройки сверху, выставьте параметры как на скриншоте и нажмите «Начать».
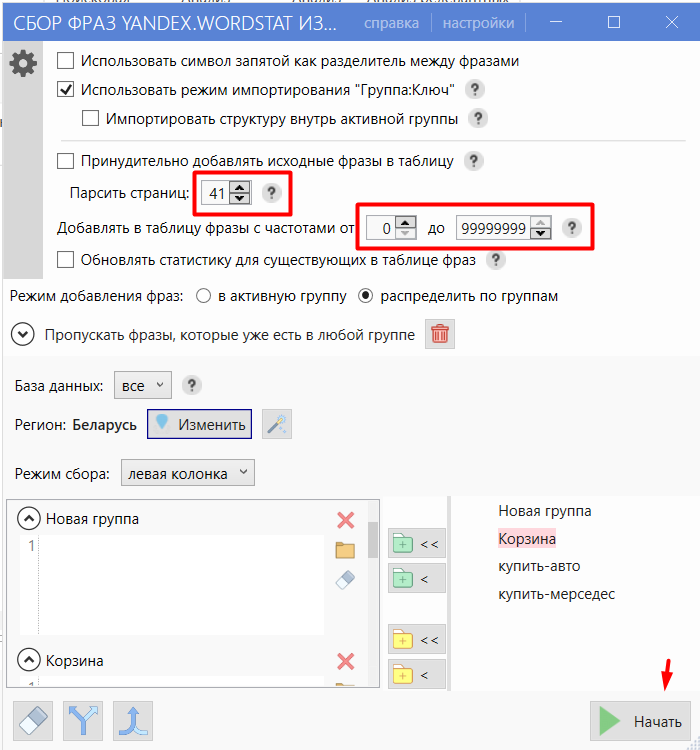
- 04 Процесс парсинга виден внизу. Скорость зависит от количества и частотности добавленных фраз.
Сбор минус-слов
Минус-фразы можно собирать напрямую в Key Collector или через выгрузку запросов в генератор минус-слов (например, livepage.ua/tools/keys). Рекомендуем генератор — так удобнее. Рассмотрим оба способа.
Способ 1. С помощью Key Collector
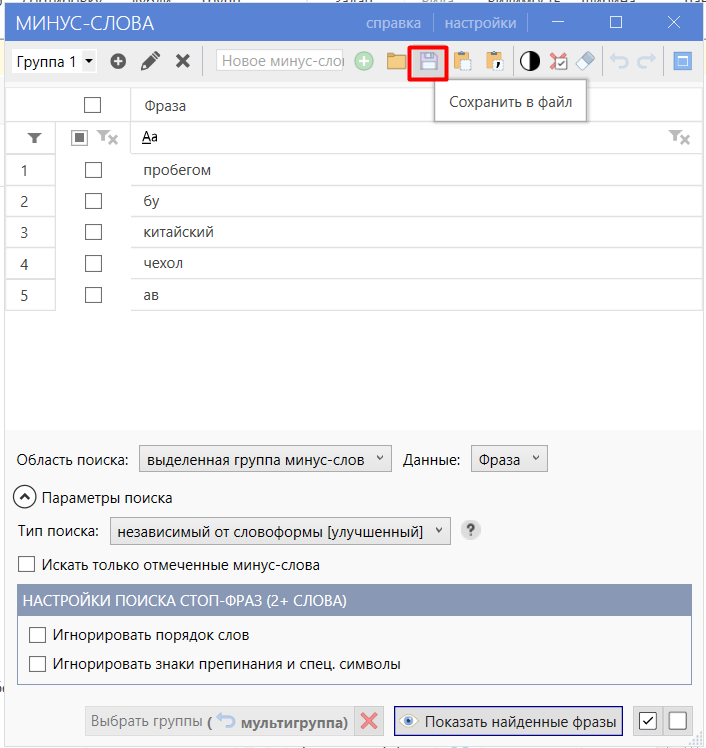
В рабочей области просматриваем фразы, находим ненужные слова и нажимаем «Отправить в минус-слова» напротив фразы.
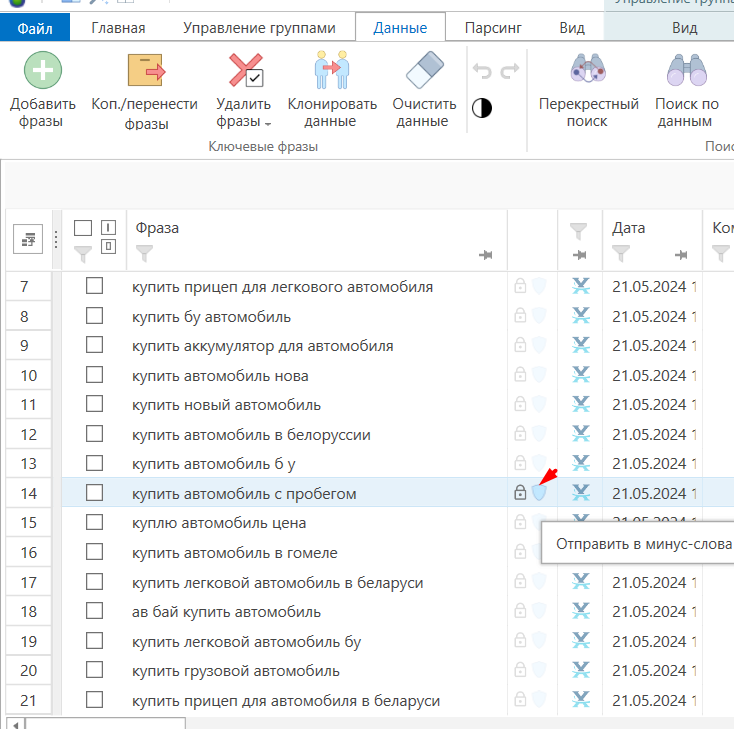
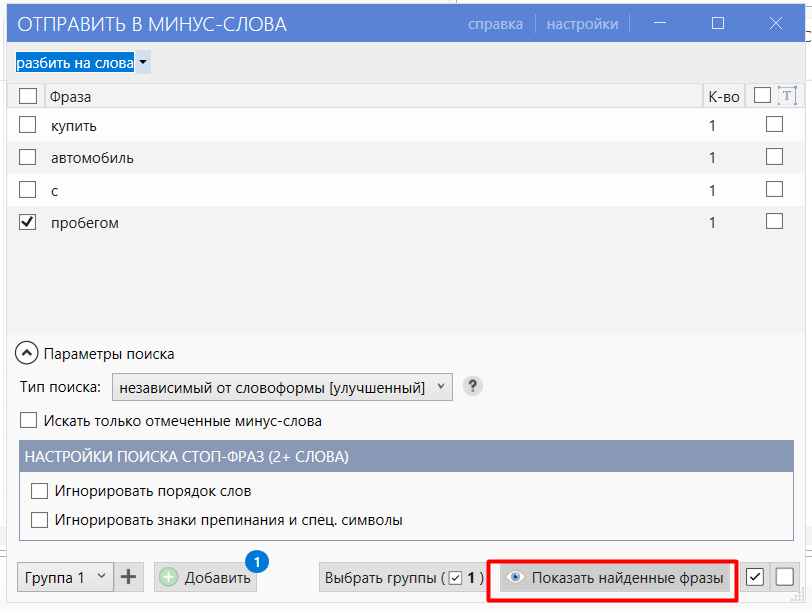
Пример: интересует слово «пробегом». В окне добавления минус-слов выбираем сверху «разбить по словам», отмечаем галкой ненужное слово и нажимаем «Добавить».
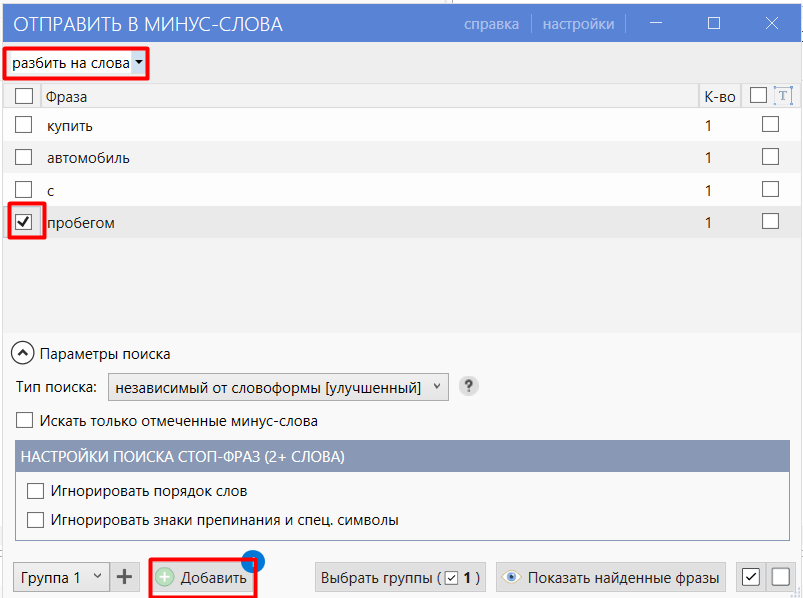
Пример 2: нужно исключить целую фразу — выбираем «исходные фразы целиком», отмечаем фразу галкой и нажимаем «Добавить».
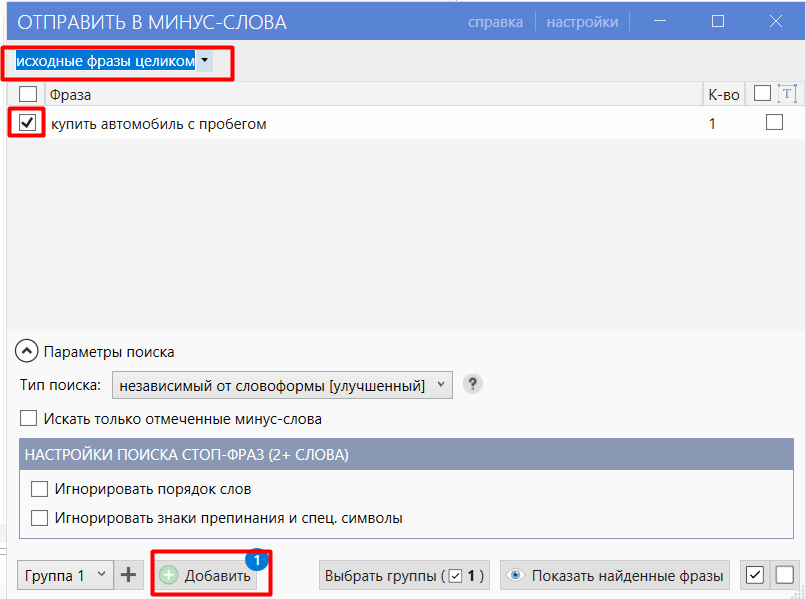
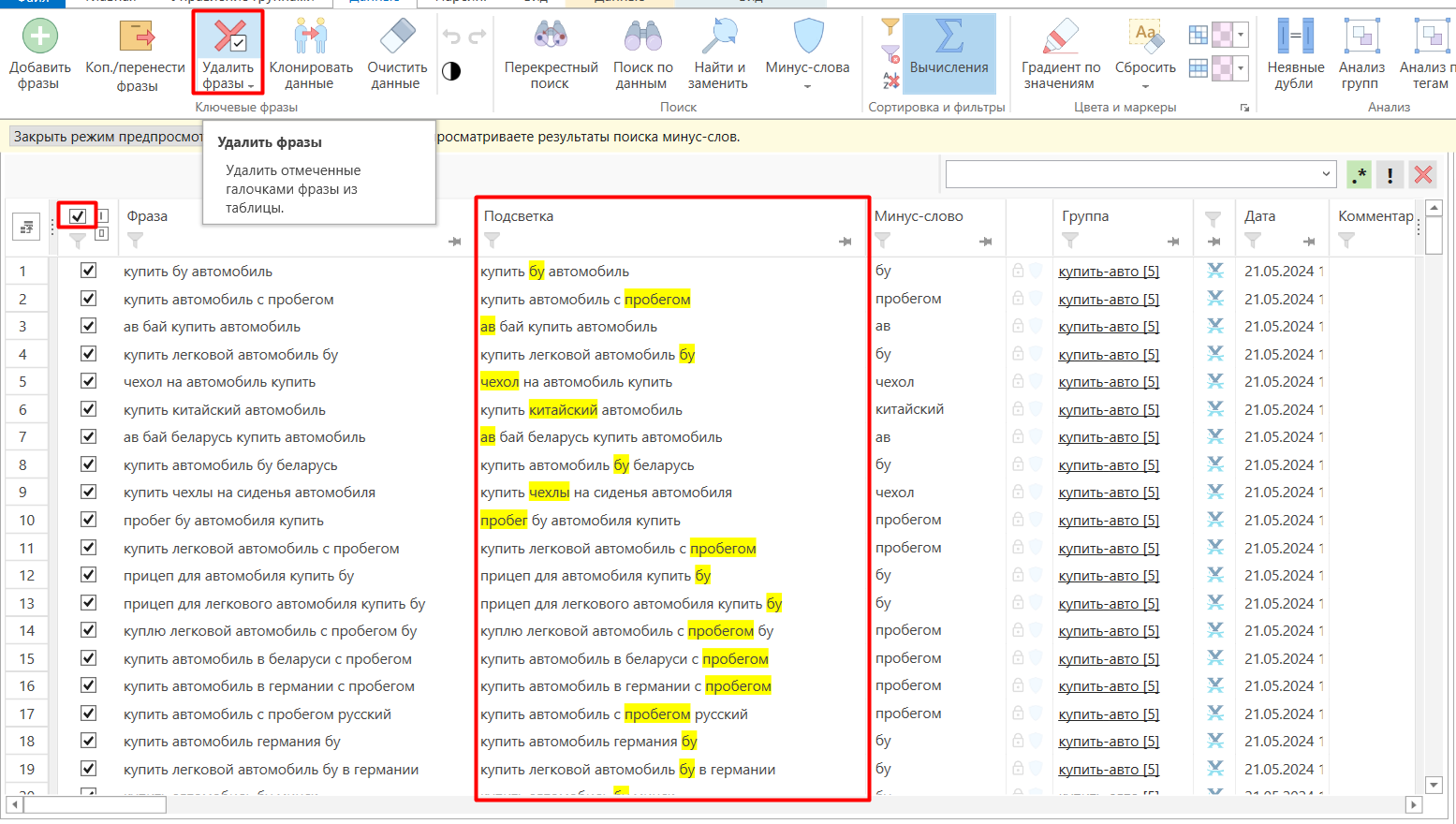
После добавления нажимаем «Показать найденные фразы» — программа подсветит все фразы с выделенным словом. Выбираем их чек-боксом и на вкладке «Данные» нажимаем «Удалить фразы».
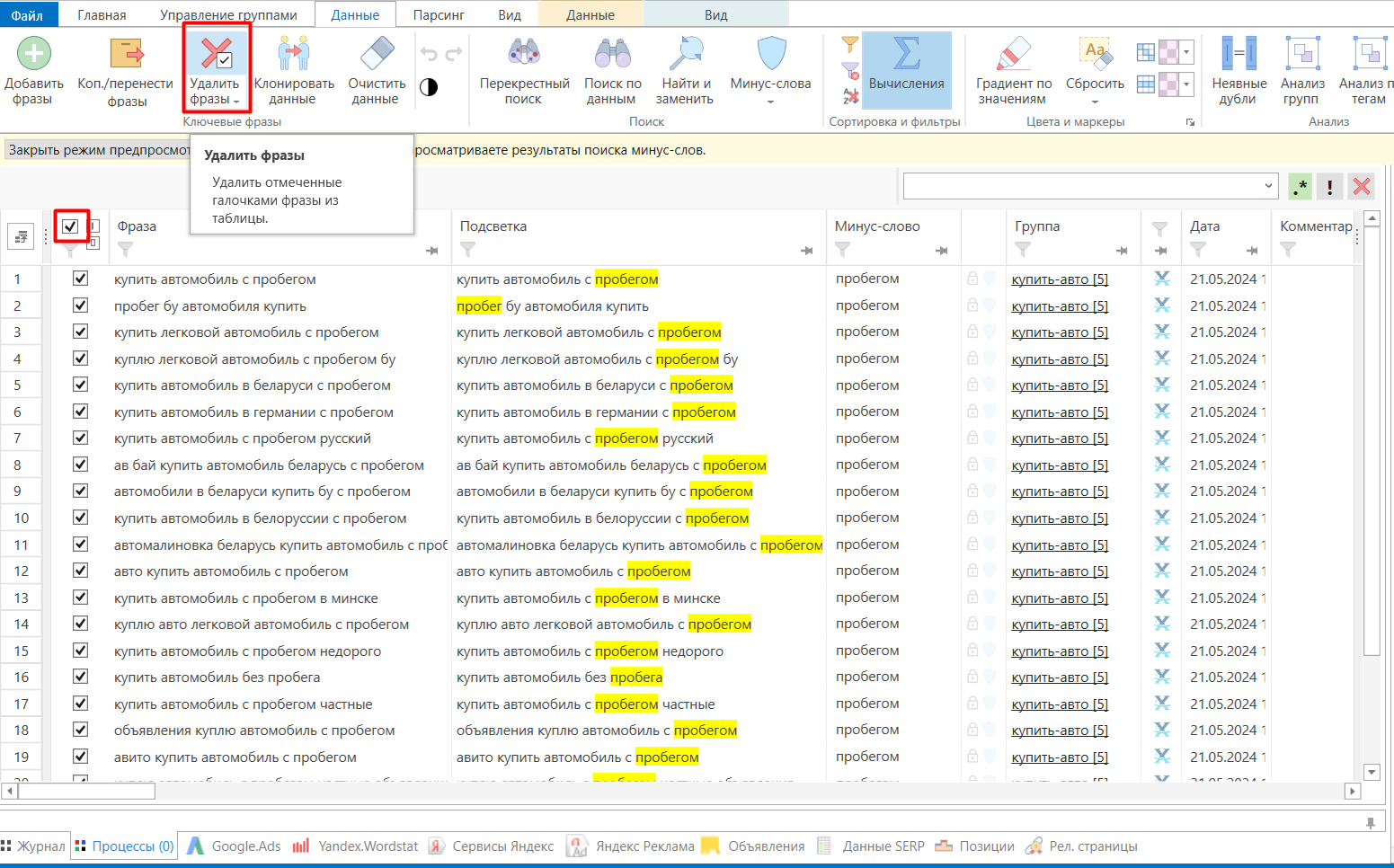
Обязательно просматривайте запросы перед удалением: случайно можно заминусовать предлог или важное слово. Учитывайте, что Key Collector сам склоняет минус-фразы — добавив слово в одном склонении, вы, скорее всего, исключите и фразу в другом. Например, отминусовав «пробегом», сразу исключите и «пробег».
Способ 2. Через экспорт и генератор минус-слов
Сначала объединяем фразы в «мультигруппу»: выделяем группы мышкой с зажатым Shift (все подряд) или Ctrl (выборочно). Пустую «Новую группу» и корзину можно не выделять.
Нажимаем кнопку «Файл» сверху, далее «Экспорт» → «Фразы и статистика» и сохраняем файл XLS. Открываем его в Excel, копируем столбец фраз полностью и переходим в генератор минус-слов.
Загружаем фразы в генератор и собираем слова, кликая по ненужным.
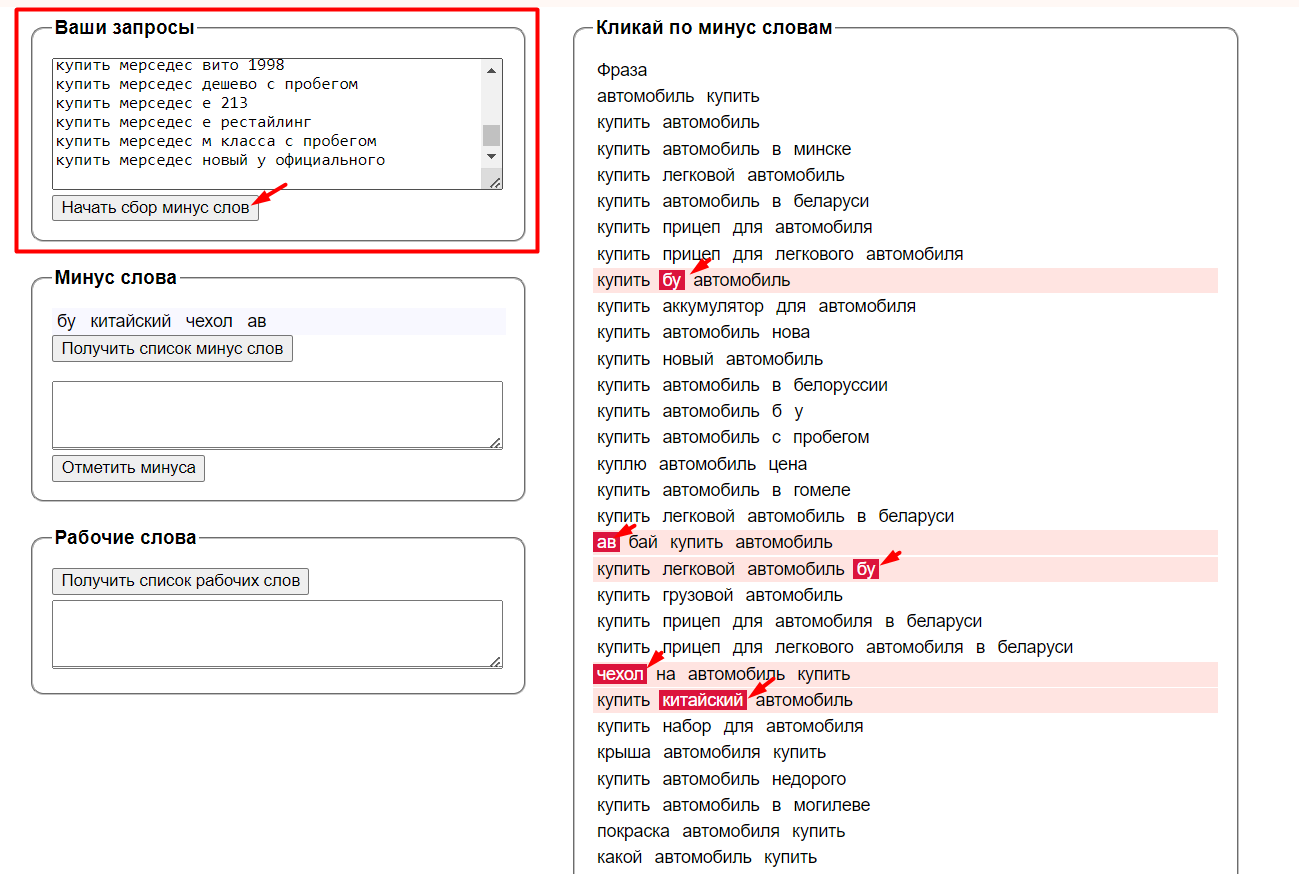
Когда минус-слова собраны, нажимаем «Получить список минус-слов», выделяем все слова (Ctrl+A) и копируем (Ctrl+C).
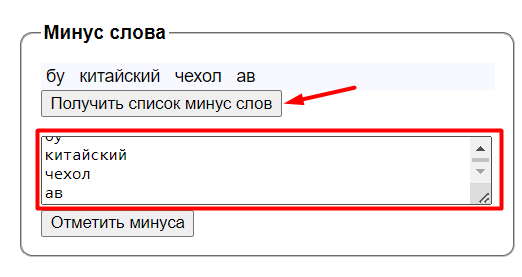
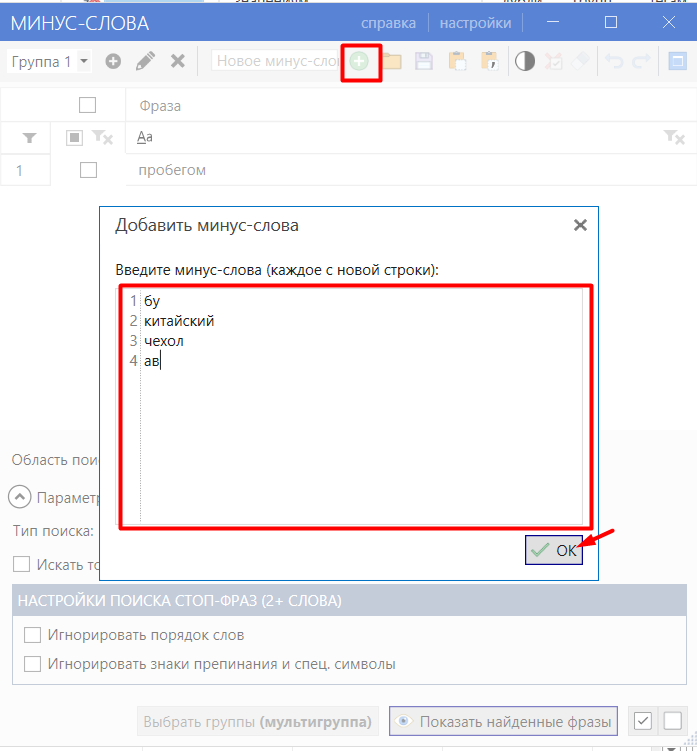
Возвращаемся в Key Collector: вкладка «Данные» → «Минус-слова». Нажимаем «+», добавляем слова в открывшееся окно и сохраняем.

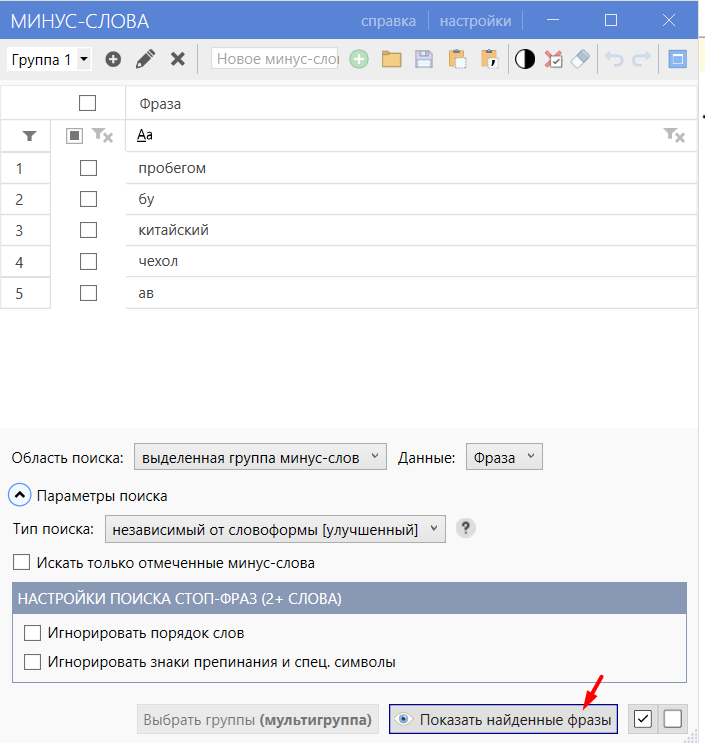
Нажимаем «Показать найденные фразы», проверяем по подсветке, что всё верно, выбираем фразы чек-боксом и нажимаем «Удалить фразы».
Удаление неявных дублей
Неявные дубли — это две фразы из одного набора слов в разном порядке: «цветная капуста» и «капуста цветная» — дубли, а «капуста цветная» и «капуста цветная свежая» — нет. Их нужно удалять: по сути это одна фраза, и при фразовом или широком соответствии они и так покажутся. Если используете точное соответствие с фиксированным порядком слов — чистить дубли не обязательно.
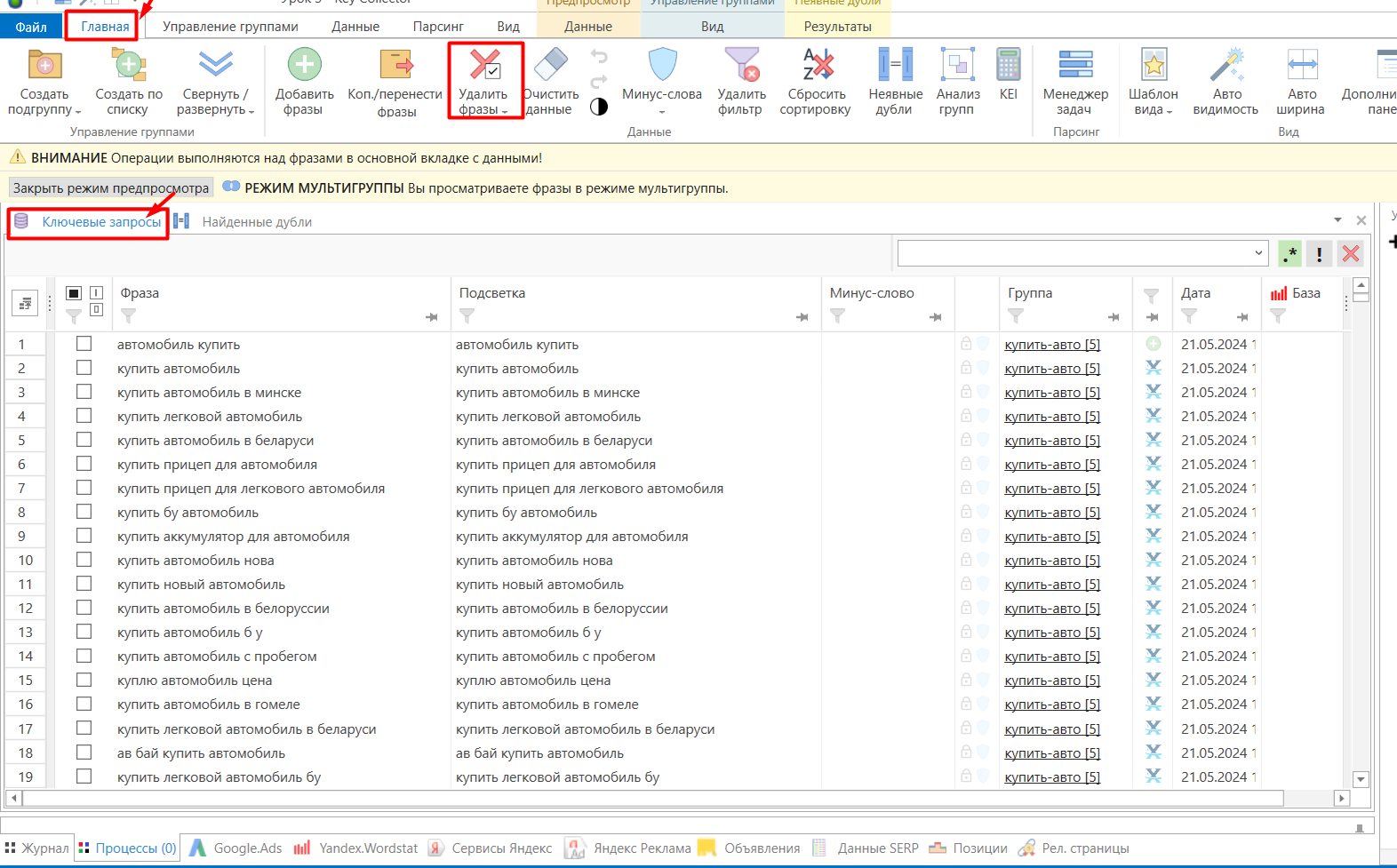
- 01 Сначала выберите группы в «мультигруппу» (Shift — все подряд, Ctrl — выборочно). Затем вкладка «Главная» → пункт «Неявные дубли».

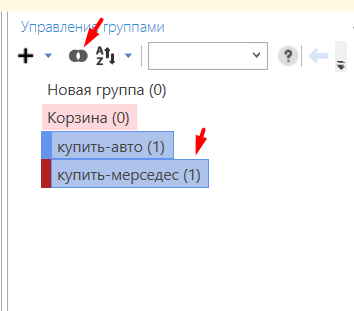
- 02 В открывшемся окне проверьте настройки и нажмите «Найти». Когда программа отработает, откроется вкладка с результатами поиска дублей.
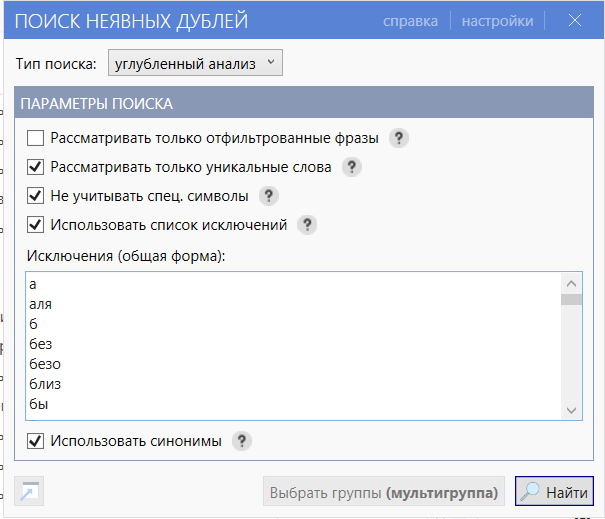
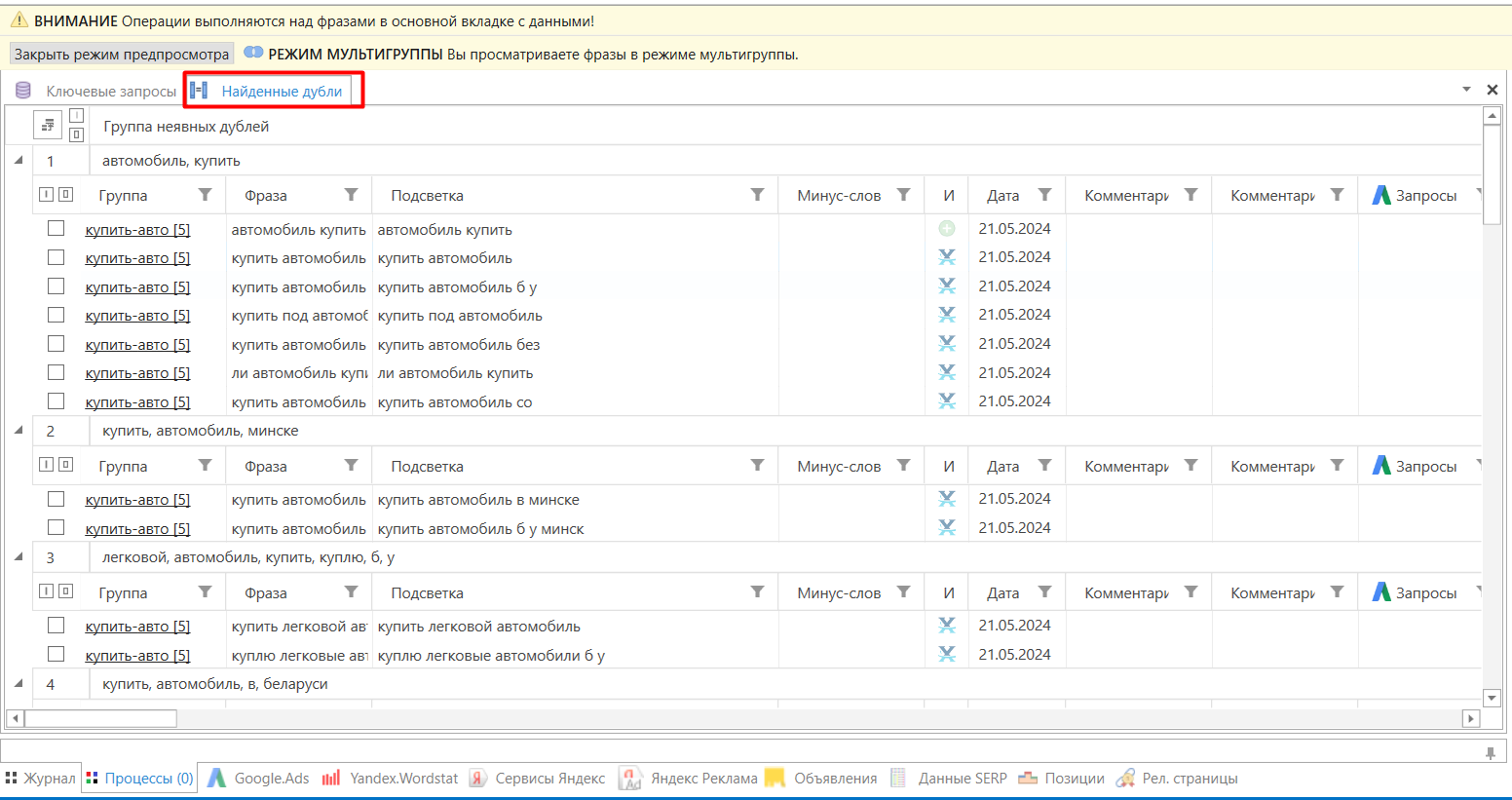
- 03 Настройте «Умную отметку» (стрелка рядом с кнопкой): сначала выберите «Отметить все фразы кроме имеющих максимальное числовое значение», источник данных — «База», сохраните.

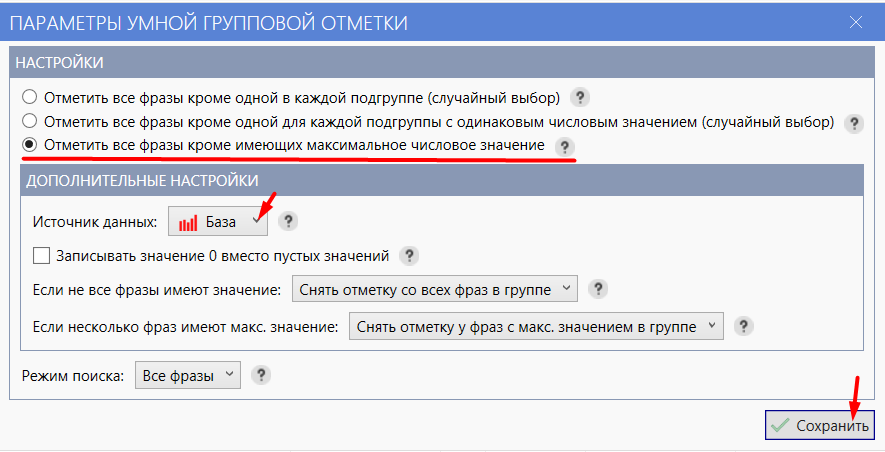
- 04 Нажмите «Умная отметка» ещё раз, чтобы фразы отметились, затем «Применить изменения».
- 05 Перейдите на основную вкладку «Ключевые фразы» → «Главная» → «Удалить фразы».
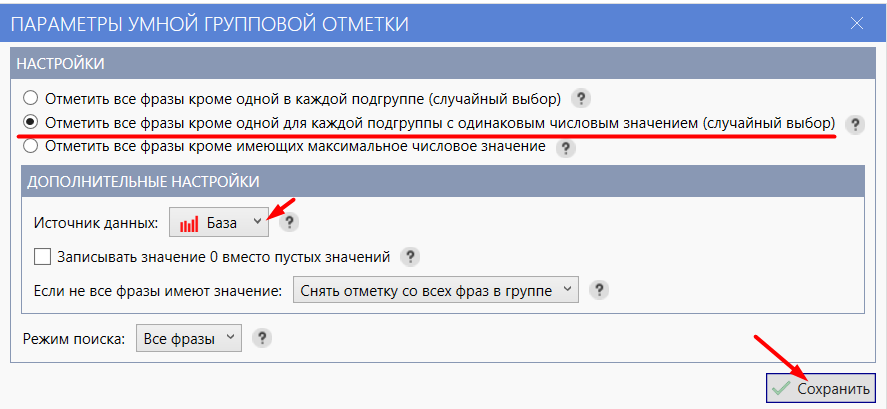
- 06 Запустите поиск дублей ещё раз. Теперь в параметрах выберите «Отметить все фразы кроме одной для каждой подгруппы с одинаковым числовым значением (случайный выбор)», источник — «База». Повторите отметку и удаление.
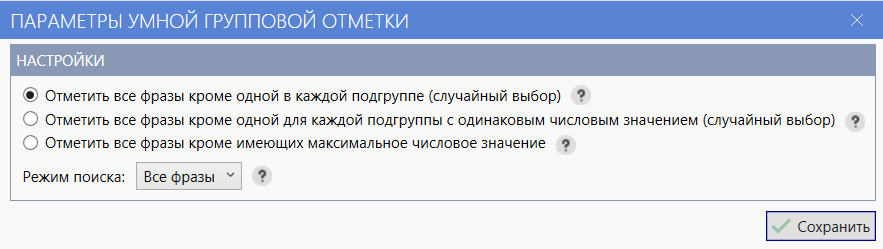
- 07 Третий проход: «Отметить все фразы кроме одной в каждой подгруппе (случайный выбор)» — и снова удалите фразы.
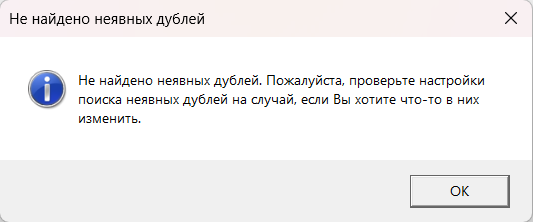
После этого неявных дублей остаться не должно — при повторном поиске вы получите такое уведомление. Соблюдать именно такой порядок важно, чтобы при случайном выборе не удалить нужные фразы.
Чистка и кластеризация запросов
После сбора минус-слов и удаления дублей всё же могут затесаться ненужные фразы — перепроверьте каждую группу. Для рекламы старайтесь оставлять максимально коммерческие фразы (с приставками «купить», «заказать», «цена» и т.д.).
- 01 Просматриваем запросы, удаляем ненужные или добавляем их в минус-слова.
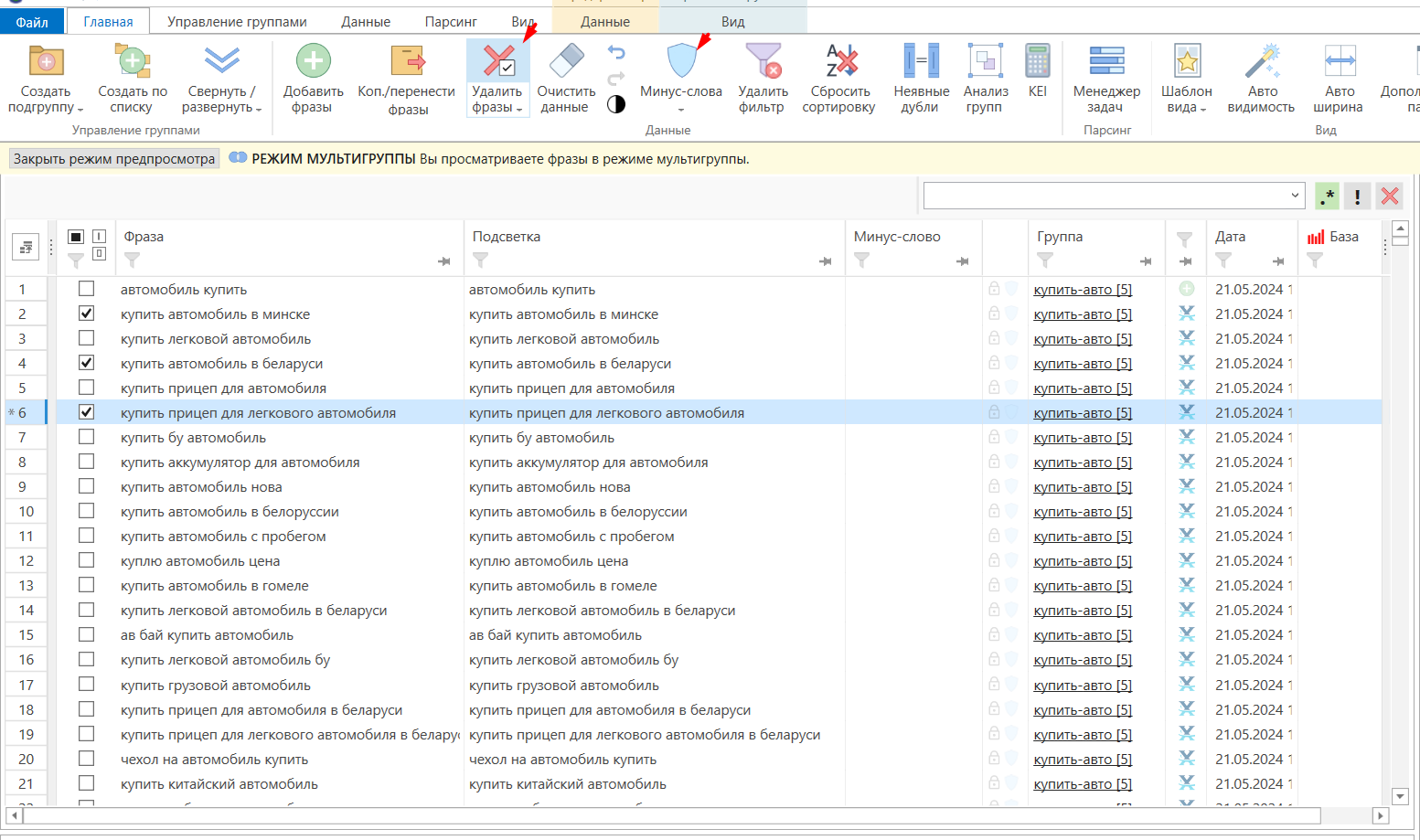
- 02 Кластеризация — распределение запросов по группам по смыслу: «купить автомобиль» и «купить мерседес» — в разные группы. Хороший тон — до 15–20 запросов в группе. Новые группы создаются плюсом в рабочей области справа; называйте их понятно (например, «купить-пежо»).
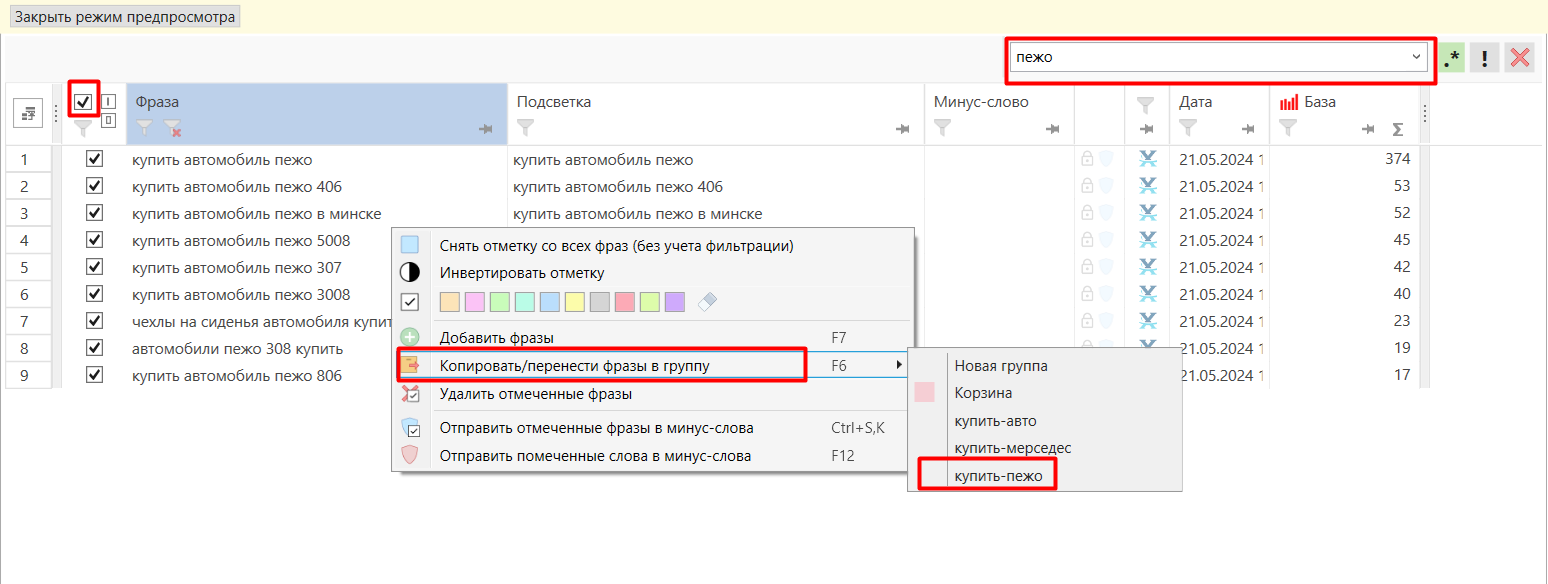
- 03 Используйте поиск сверху, чтобы найти нужные фразы. Выделите их, щёлкните правой кнопкой → «Копировать/перенести фразы в группы» и выберите группу. Фильтр потом можно снять отдельной кнопкой.
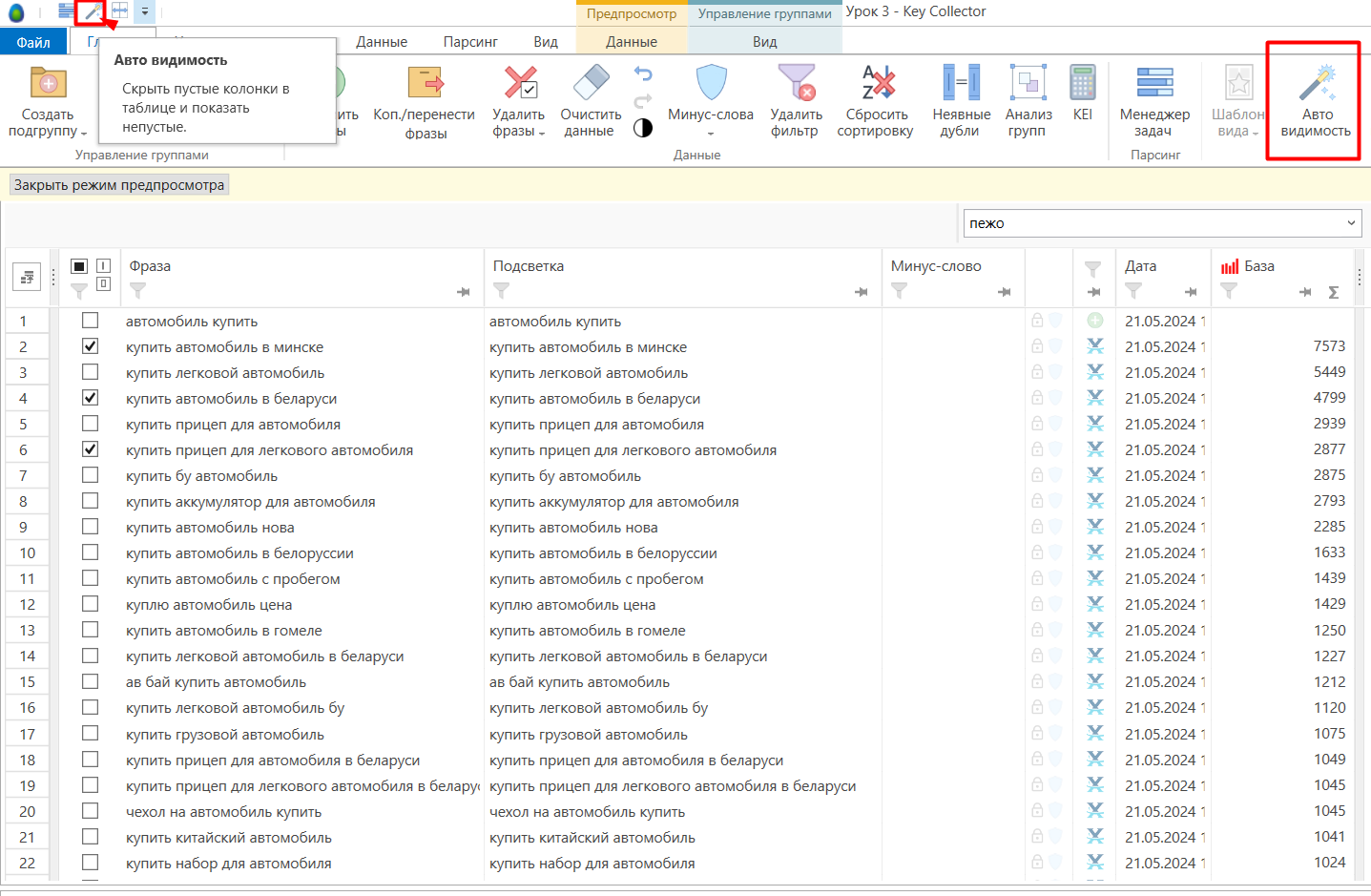
- 04 Чистим запросы по частоте: для рекламы берём то, что реально ищут — рекомендуем от 10 запросов в месяц. Чтобы скрыть пустые столбцы, используйте «Волшебную палочку».
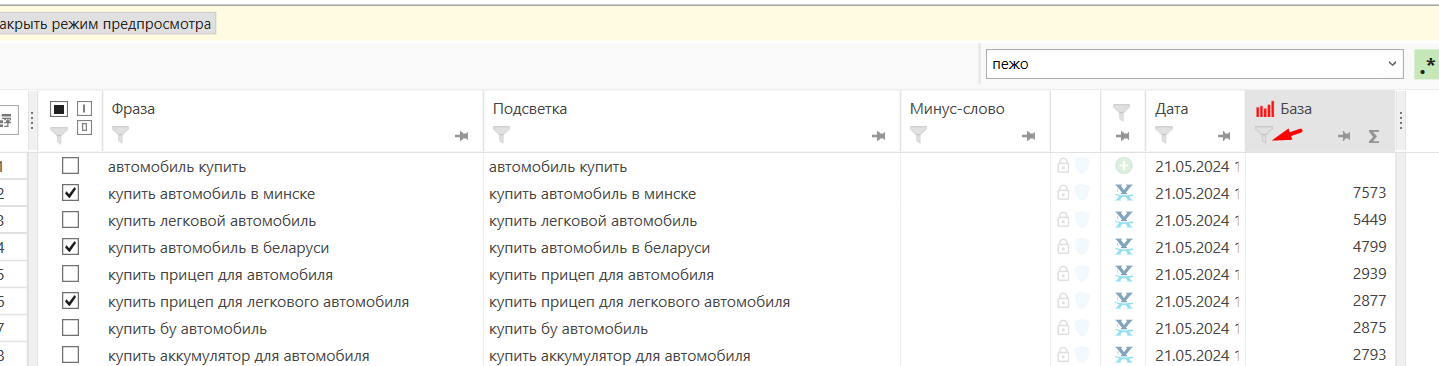
- 05 Выберите фильтр рядом со столбцом «База» и выставьте «меньше 10» (или другое значение — зависит от собранной семантики).
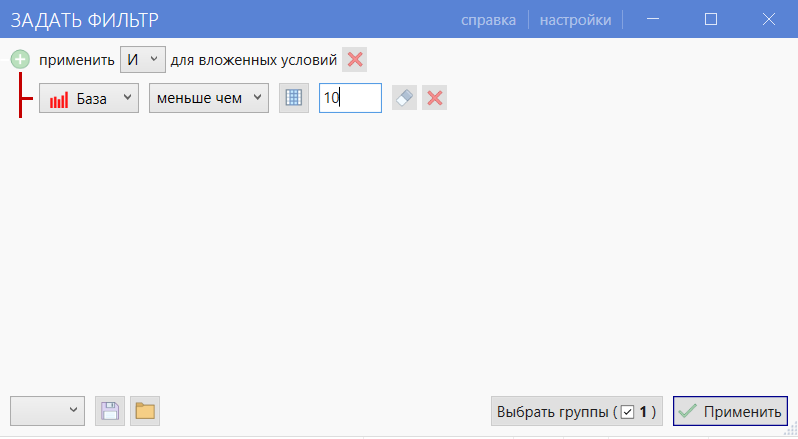
- 06 Выделите отфильтрованные фразы и нажмите «Удалить фразы».
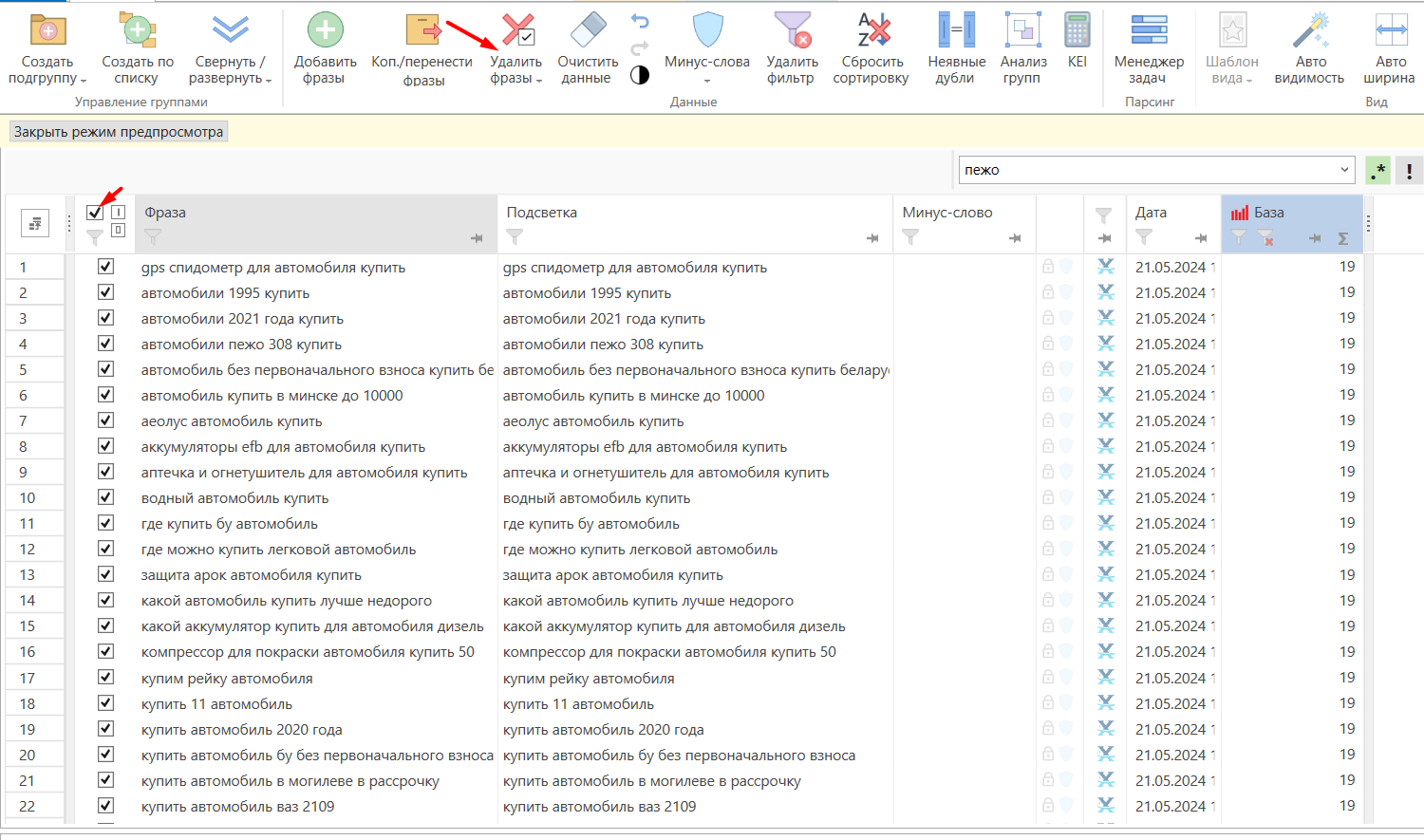
Помните: пороговая частота зависит от тематики. В узкоспециализированных нишах частота до 10 — нормально, а где-то и 20 слишком узко. Смотрите по уже собранному ядру.
Выгрузка итогового файла и файла минус-слов
Последний этап — выгружаем результаты работы.
- 01 Ключевые слова: сверху слева «Файл» → «Экспорт» → «Фразы и статистика». Сохранится Excel-файл с фразами, группами и частотой — в таком виде уже можно отправлять клиенту на согласование.
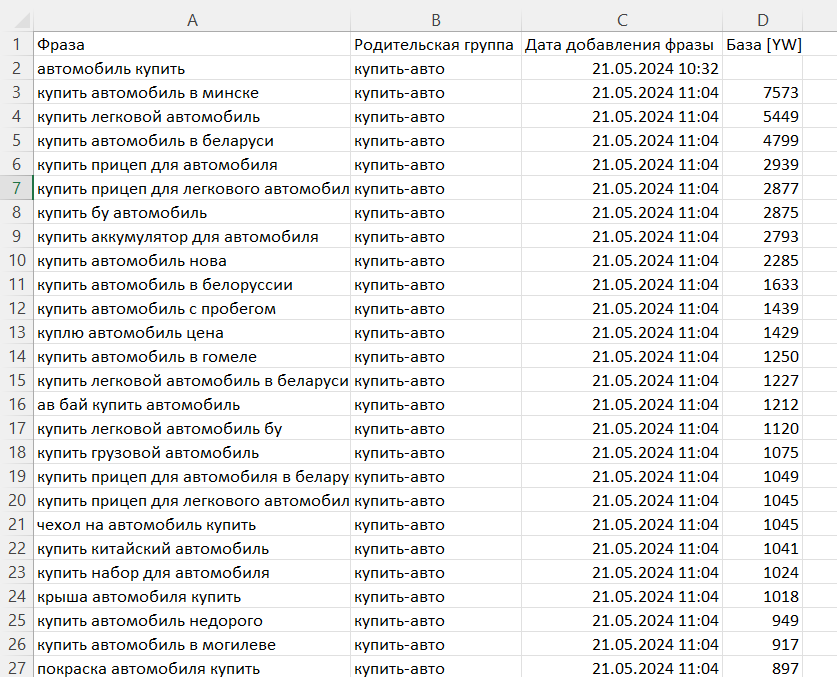
Мы обычно переносим фразы в Google Sheets — без частот и с понятными названиями столбцов, чтобы клиент мог быстро оставить комментарий. Пример такого файла:
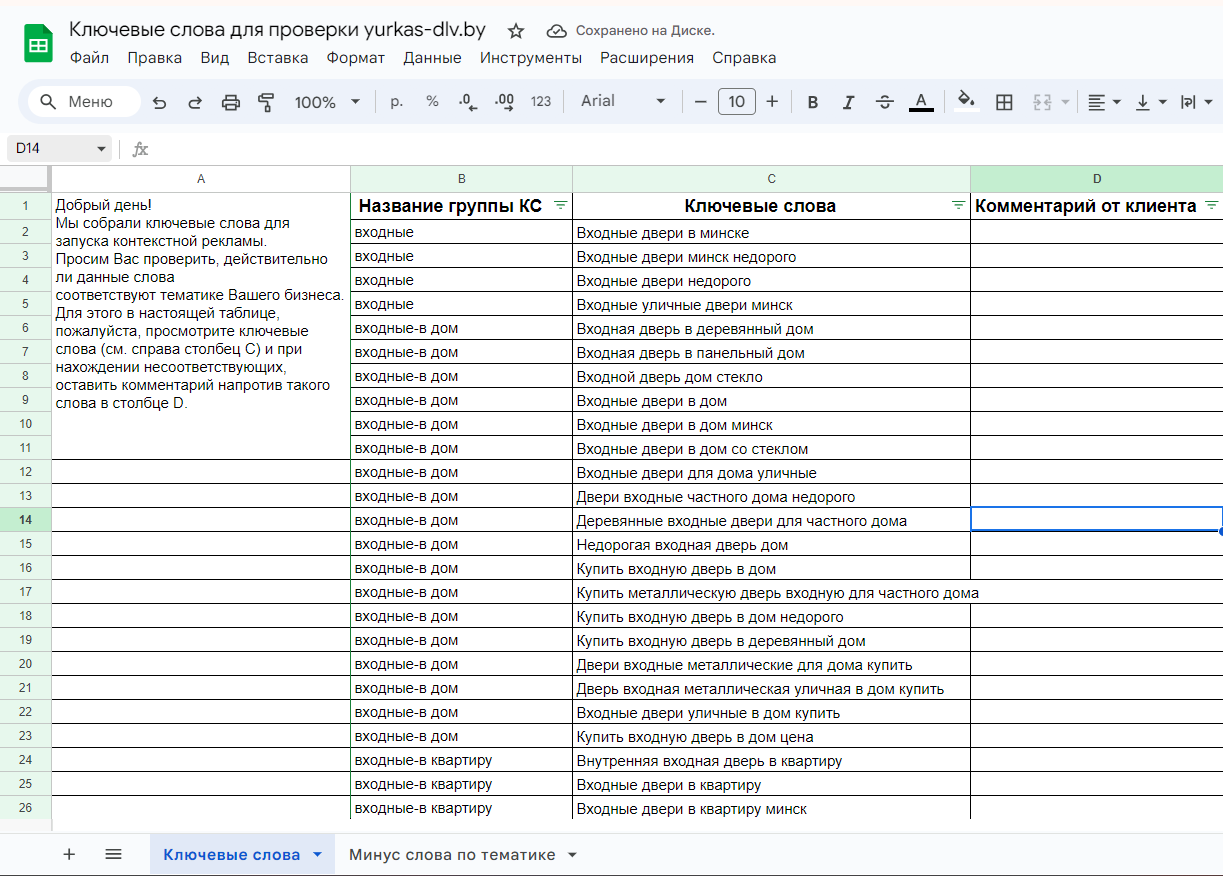
- 02 Минус-слова: на вкладке «Главная» нажмите кнопку «Минус-слова», затем «Сохранить в файл». Они сохранятся в текстовом формате — скопируйте их в Google Sheets на лист с минус-словами.

Wordstat DeepDive делает глубокий обход Вордстата, собирает минус-слова и выгружает готовый файл — без Key Collector и платных модулей.
Не хотите возиться с семантикой сами? Соберём ядро и настроим рекламу под ключ — услуга Контекстная реклама.
После него ядро нужно почистить, сгруппировать и разнести по страницам — иначе тысячи запросов останутся таблицей. Мы делаем это как часть продвижения, а не отдельной услугой «сдать ядро».
Частые вопросы
Чем парсинг отличается от простого сбора из Вордстата? +
Как долго идёт парсинг большого ядра? +
Хотите так же — но в своём проекте?
Бесплатно посмотрим вашу рекламу и аналитику и покажем, где теряются заявки. Без обязательств.
Кейсы, разборы и новости digital — без воды.